Back
The Failure History Method for Predictive Maintenance ROI Calculation
Jun 7, 2024
Predictive Maintenance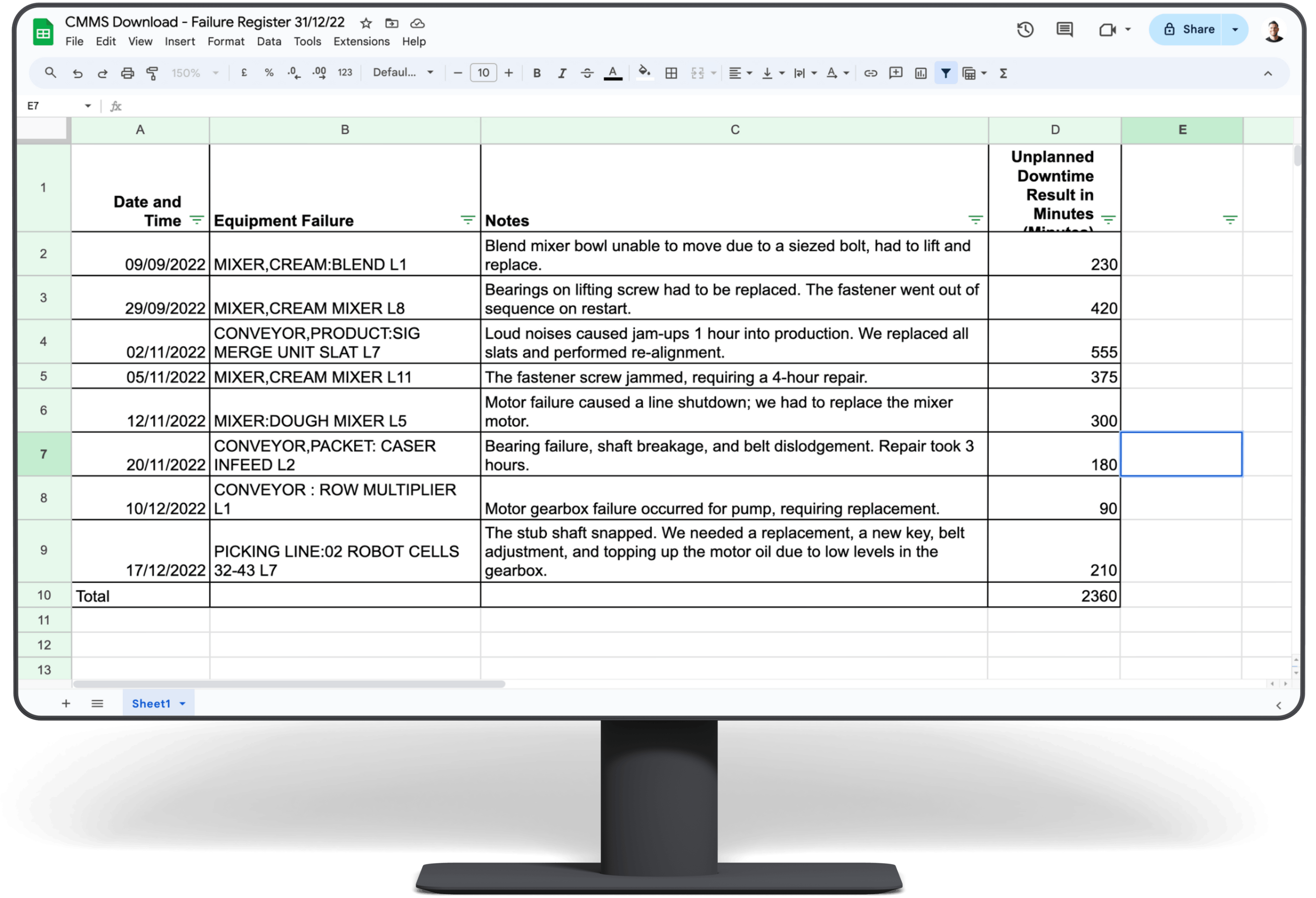
In this post, we guide you through six steps using the failure history method to estimate the ROI of implementing Predictive Maintenance Software.

JP Picard
JP is the Co-Founder and CEO of Factory AI. Previously, he held senior sales leadership roles at Salesforce and Zipline, supporting executive teams in their digital transformation journeys. His passion for reliability and maintenance grows as Factory AI partners with clients to tackle unique challenges